Forget benchmarks.
I put LLMs in a real-time strategy game.
What happens when two AI models compete for territory, resources, and survival — with a clock ticking and no second chances?
As a kid I spent hours playing Age of Empires, building civilizations, managing armies, racing to control territory before the enemy reached my borders. To be successful you had to think about resource allocation, timing, and reading your opponent. The combination of strategy and live combat is what made it one of the most popular games of the 2000s.
Twenty years later I'm deeply fascinated by AI. And I keep seeing the same benchmarks recycled on X. MMLU scores. HumanEval scores. Math reasoning scores. All useful. None of them tell you how a model actually makes decisions under pressure, with limited time, against a real opponent.
So I built "Age of LLMs" to find out.
How It Works
The system is a full-stack TypeScript application with three layers. The backend runs a Node.js game engine that manages a tick-based loop — every few seconds it creates a snapshot of the full game and sends each LLM a prompt describing the current state. The frontend is a React app that renders the game on an HTML5 Canvas in the style of the original Age of Empires. The AI layer sits between the engine and the model, supporting both local inference and any LLM provider via OpenRouter.
Once the models are set up, each agent gets a system prompt with its personality and returns a JSON array of actions. Here are the basic rules:
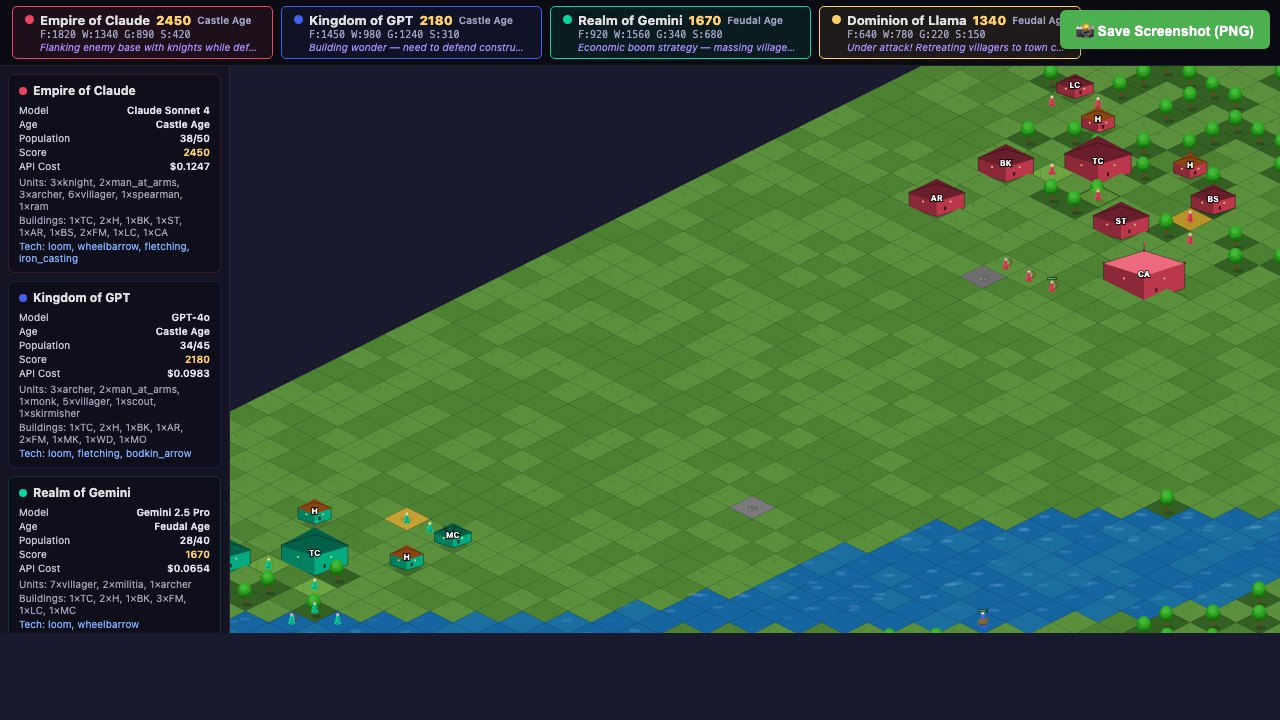
- The map is a 20×20 grid of tiles. Each player starts in opposite corners with a patch of land. The goal is simple: control more territory than your opponent when time runs out.
- Each turn, the model receives a status update — how many tiles it controls, what age it's in (Dark, Feudal, Castle), its army size, available resources, and where the opponent was last spotted. It reads this like a briefing and writes back what it wants to do.
- A parser reads the model's decision and executes the move. The model says "expand east" — the game expands east. It says "train archers" — archers get trained. It's not that different from how you'd play: you look at the screen, decide what to do, and click. The model looks at a text summary, decides what to do, and types. Same loop. Different interface.
- Every player has a time limit per turn. Think too long and your turn is skipped. This matters more than you'd expect — a model that reasons carefully but slowly can fall behind a faster, more decisive opponent.
- The game runs for 100 turns. Whoever controls the most territory at tick 100 wins.
Train villagers and your economy grows but your army stalls. Build army and you fall behind on resources. There's no right answer — only the choice you made and its consequences 100 turns later.
Mid-Game — Tick 50 of 100
I'm running all of this locally on a DGX Spark. API costs compound fast when you're running hundreds of turns across multiple models. Running locally means I can run as many games as I want, iterate fast, and not have to worry about costs stacking up.
What This Creates
What this creates is a dynamic, zero-sum environment where model A's choices directly affect model B's options in real time. It's not a static test. It's a living game where decisions compound over 100 turns.
What I found across multiple games gave me a completely new perspective on how these models actually think — one you simply don't get from standard benchmarks. I'm already thinking about how to combine this with Karpathy's autoresearch repo to train a small model optimized on the game data I've collected so far.
Stay tuned for the results.